Microservices: Designing Highly Scalable Systems
Microservices: Designing Highly Scalable Systems
The goal of this article it to equip you with all the knowledge required to design a robust, highly scalable micro services architecture.
Microservices are an approach to distributed systems that promote the use of finely grained services with their own lifecycles, which collaborate together. Because microservices are primarily modeled around business domains, they avoid the problems of traditional tiered architectures. Microservices also integrate new technologies and techniques that have emerged over the last decade, which helps them avoid the pitfalls of many service-oriented architecture implementations.
Principles of Microservices
- Microservices should not share code or data
- Small, and Focused on Doing One Thing Well
- Autonomous
- Independence and autonomy are more important than code re-usability
- No single point of failure
- Each micorservice should be responsible for a single system function or process.
- No direct communication allowed, Should use event/message bus.
Key Benefits
- Technology Heterogeneity
- Resilience
- Scaling
- Ease of Deployment
- Organizational Alignment
- Composability
- Optimizing for Replaceability
What About Service-Oriented Architecture?
Service-oriented architecture (SOA) is a design approach where multiple services collaborate to provide some end set of capabilities. Communication between these services occurs via calls across a network rather than method calls within a process boundary.
Typical Microservices Architecture
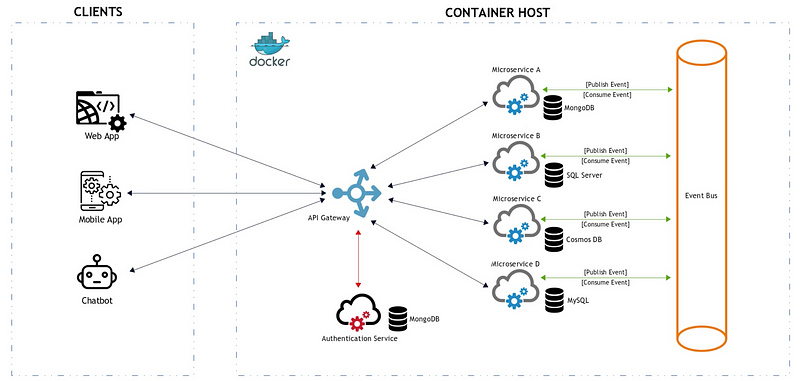
It provides a high level overview of all the building blocks of a typical micro-services architecture. A typical microservices architecture consists of the following components or building blocks.
Client applications that form the presentation layer of the architecture. Where each client application would only be responsible for UI presentation and for consuming the back-end microservices.
In this example we have a web application mobile app and chatbot. The second building block is the container host.
In this example we have a docker host, where our microservices are deployed. Each microservice would typically contain the domain or business logic, and database access logic that are required to facilitate one specific application function or process. Notice that each microservice has its own database.This allows microservices to be totally decoupled from each other and it even gives you the ability to use a different database type for each microservice, should you wish to do so.
Yet another important building block is an API gateway as a centralized entry point to the back-end microservices.An API Gateway allows client to micro services communications over HTTP instead of calling each micro-service directly. Clients can make their request to one or more API gateways that will route the HTTP requests to the desired microservices that will execute the command and query requests.
Another critical component in a microservices architecture is an authentication service. An authentication service is used to authenticate client applications and provide them with an access token or JWT. This access token needs to be sent with their HTTP request to securely access each microservice. A client application would therefore typically make two HTTP requests. The first to obtain the access token, and secondly to make the actual request to the desired microservice via an API Gateway. Access token are generally only active for a configurable time. Therefore if for example a token is valid for five minutes a client can make multiple requests before the token expires. Removing the need to make a new token request with every call. There should be a balance between the access frequency and expiration time.
Keeping in mind that the shorter the expiration time the more secure the request.
Another important building block and key enabler of a microservices architecture is an event bus. An event bus allows microservices to communicate with each other through asynchronous event based communication. Were microservices can publish events to the event bus and listen for specific events that they can consume and process.
This was a high level overview presented in the form of a deployment view of a typical microservices architecture.
What is an API Gateway?
When you design and build large or complex microservice-based applications with multiple client apps, a good approach to consider can be an API Gateway. This pattern is a service that provides a single-entry point for certain groups of microservices. It’s similar to the Facade pattern from object-oriented design, but in this case, it’s part of a distributed system. The API Gateway pattern is also sometimes known as the “backend for frontend” (BFF) because you build it while thinking about the needs of the client app.
Therefore, the API gateway sits between the client apps and the microservices. It acts as a reverse proxy, routing requests from clients to services. It can also provide other cross-cutting features such as authentication, SSL termination, and cache.

Why consider API Gateways instead of direct client-to-microservice communication
In a microservices architecture, the client apps usually need to consume functionality from more than one microservice. If that consumption is performed directly, the client needs to handle multiple calls to microservice endpoints. What happens when the application evolves and new microservices are introduced or existing microservices are updated? If your application has many microservices, handling so many endpoints from the client apps can be a nightmare. Since the client app would be coupled to those internal endpoints, evolving the microservices in the future can cause high impact for the client apps.
If you don’t have API Gateways, the client apps must send requests directly to the microservices and that raises problems, such as the following issues:
- Coupling
- Too many round trips(several calls to multiple services)
- Security issues(microservices exposed to the “external world”)
- Cross-cutting concerns: Each publicly published microservice must handle concerns such as authorization and SSL. In many situations, those concerns could be handled in a single tier so the internal microservices are simplified.
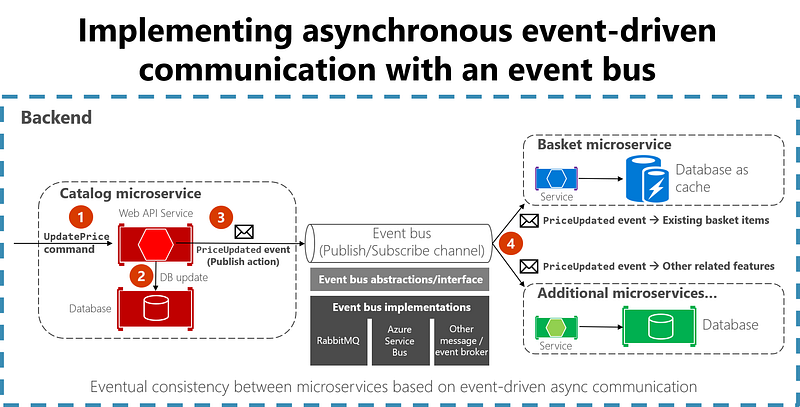
Event-Driven Communication Using an Event Bus
When you use event-based communication, a microservice publishes an event when something notable happens, such as when it updates a business entity. Other microservices subscribe to those events. When a microservice receives an event, it can update its own business entities, which might lead to more events being published. This is the essence of the eventual consistency concept. This publish/subscribe system is usually performed by using an implementation of an event bus. The event bus can be designed as an interface with the API needed to subscribe and unsubscribe to events and to publish events. It can also have one or more implementations based on any inter-process or messaging communication, such as a messaging queue or a service bus that supports asynchronous communication and a publish/subscribe model.
What is Command and Query Responsibility Segregation (CQRS)?
This pattern separates read and update operations for a data store. Implementing CQRS in your application can maximize its performance, scalability, and security. The flexibility created by migrating to CQRS allows a system to better evolve over time and prevents update commands from causing merge conflicts at the domain level.
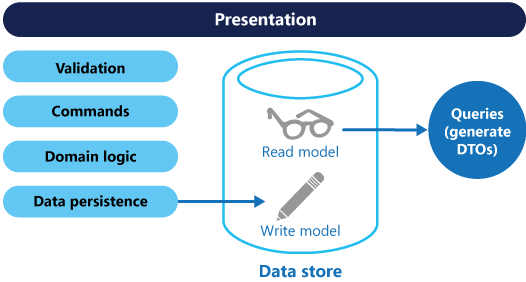
Benefits of CQRS include:
- Independent scaling. CQRS allows the read and write workloads to scale independently, and may result in fewer lock contentions.
- Optimized data schemas. The read side can use a schema that is optimized for queries, while the write side uses a schema that is optimized for updates.
- Security. It’s easier to ensure that only the right domain entities are performing writes on the data.
- Separation of concerns. Segregating the read and write sides can result in models that are more maintainable and flexible. Most of the complex business logic goes into the write model. The read model can be relatively simple.
- Simpler queries. By storing a materialized view in the read database, the application can avoid complex joins when querying.
CQRS & Event Sourcing
The CQRS pattern is often used along with the Event Sourcing pattern. CQRS-based systems use separate read and write data models, each tailored to relevant tasks and often located in physically separate stores. When used with the Event Sourcing pattern, the store of events is the command model, and is the official source of information. The query model of a CQRS-based system provides materialised views of the data, typically as highly denormalised views. These views are tailored to the interfaces and display requirements of the application, which helps to maximize both display and query performance.

Saga Pattern
The saga design pattern is a way to manage data consistency across microservices in distributed transaction scenarios. A saga is a sequence of transactions that updates each service and publishes a message or event to trigger the next transaction step. If a step fails, the saga executes compensating transactions that counteract the preceding transactions.

Assume microservice create an order in a pending state. The order saga orchestrator then publishes a process payment command event to the event pass the payment. Payment Microservice within listen for a process payment command event and a team to process the payment. If it succeeds it would publish a payment process event to the event pass. However this time the order saga orchestrator will consume the payment process event instead of the shipping micro servers. The orders saga orchestrator would then publish a ship order command that the shipping micros service would consume and process if it is successful in its attempts it would reply to the orders saga orchestrator by publishing an order shipped event to the event Press.
Finally the orders saga orchestrator would consume the orders shipped event and update the order as approved.
Again this is a scenario where everything was successful. Let us look at how failures are handled in the orchestration based saga approach.
The orders saga orchestrator could also listen to failure type events. If the payment service publishes an insufficient funds event will the shipping micros service publishers are not shipped event. The order saga orchestrator would handle those events and update the order as reject it. It would also take the responsibility to execute a series of compensating transactions to undo all the changes.
Unified logging for microservices applications
Logging uses discrete event messages to track and report application data in a centralized way. Log events provide an overview of application execution state, track code errors or application failures, and deliver informational messages. Automation can read event logs and notify relevant parties if events meet a criterion or threshold.
Tracing focuses on the continuous flow of an application. Tracing follows program execution through various methods and services from beginning to end, while understanding data state and transitions.
Monitoring applies application instrumentation to both tracing or logging data to provide metrics that teams can use to make informed decisions. These metrics can aggregate log or trace data in a dashboard that gives a holistic view of application health, from utilization to error count.
Architecture
The following architecture uses Azure services to build a unified logging and monitoring system.

- The application emits events from both the API and the user interface to Event Hubs and Application Insights.
- Application Insights queries short-term logging, tracing, and monitoring data.
- Stream Analytics jobs can use the Event Hubs data to trigger Logic Apps workflows.
- A Logic Apps job calls the representational state transfer (REST) endpoint of an Information Technology Service Management (ITSM) system, and sends notifications to the development team.
- Azure Sentinel automation uses Playbooks powered by Azure Logic Apps to generate security alerts.
- Keeping event logs in long-term storage allows later analysis and diagnostics with Log Analytics.
Containerized Microservices
Containerization is an approach to software development in which an application and its versioned set of dependencies, plus its environment configuration abstracted as deployment manifest files, are packaged together as a container image, tested as a unit, and deployed to a host operating system.
A container is an isolated, resource controlled, and portable operating environment, where an application can run without touching the resources of other containers, or the host. Therefore, a container looks and acts like a newly installed physical computer or a virtual machine.

Containers provides many benefits especially when it comes to portability modularity and scalability. It is undoubtably a key enabler of a successful micros services architecture.
What is container orchestration
Container orchestration refers to the automation of tasks that
relates to the scheduling and management of containers. More
specifically container orchestration is used to automate the
following tasks.
- Container deployment and provisioning
- Rescheduling of containers that fail scaling and load balancing
- Resource allocation between containers
- Container redundancy and availability
- External exposure of services
- Health monitoring of containers and hosts
Container orchestration abstracts container management complexities.It becomes especially important as the number of containers and hosts in the system increases.
Tools and Technologies
