System Design, Chapter 10: CAP Theorem
System Design, Chapter 10: CAP Theorem
Brewer first presented the CAP Theorem in the context of a web service. A web service is implemented by a set of servers, perhaps distributed over a set of geographically distant data centers. Clients make requests of the service. When a server receives a request from the service, it sends a response. Notice that such a generic notion of a web service can capture a wide variety of applications, such as search engines, e-commerce, on-line music services, or cloud-based data storage. For the purpose of this discussion, we will imagine the service to consist of servers p1, p2, . . . , pn, along with an arbitrary set of clients.
The CAP Theorem was introduced as a trade-off between consistency, availability, and partition tolerance. We now discuss each of these terms.
Consistency: informally, simply means that each server returns the right response to each request, i.e., a response that is correct according to the desired service specification.
Availability: The second requirement of the CAP Theorem is that the service guarantee availability. Availability simply means that each request eventually receive a response.
Partition-tolerance: The third requirement of the CAP theorem is that the service be partition tolerant. Unlike the other two requirements, this property can be seen as a statement regarding the underlying system: communication among the servers is not reliable, and the servers may be partitioned into multiple groups that cannot communicate with each other.
The CAP Theorem
In a network subject to communication failures, it is impossible for any web service to implement an atomic read/write shared memory that guarantees a response to every request.
The CAP theorem asserts that any networked shared-data system can have only two of three desirable properties. How- ever, by explicitly handling partitions, designers can optimise consistency and availability, thereby achieving some trade- off of all three.
Since its introduction, designers and researchers have used (and sometimes abused) the CAP theorem as a reason to explore a wide variety of novel distributed systems. The NoSQL movement also has applied it as an argument against traditional databases.
The CAP theorem states that any networked shared-data system can have at most two of three desirable properties:
- consistency equivalent to having a single up-to-date copy of the data;
- high availability (A) of that data (for updates); and
- tolerance to network partitions (P).
In some sense, the NoSQL movement is about creating choices that focus on availability first and consistency second; databases that adhere to ACID properties (atomi- city, consistency, isolation, and durability) do the opposite.
CAP theorem NoSQL database types
NoSQL (non-relational) databases are ideal for distributed network applications. Unlike their vertically scalable SQL (relational) counterparts, NoSQL databases are horizontally scalable and distributed by design — they can rapidly scale across a growing network consisting of multiple interconnected nodes.
Today, NoSQL databases are classified based on the two CAP characteristics they support:
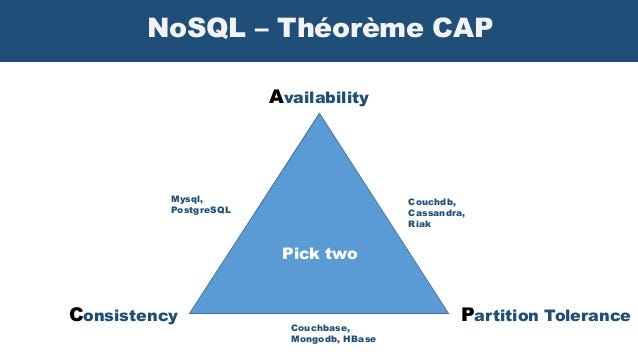
- CP database: A CP database delivers consistency and partition tolerance at the expense of availability. When a partition occurs between any two nodes, the system has to shut down the non-consistent node (i.e., make it unavailable) until the partition is resolved.
- AP database: An AP database delivers availability and partition tolerance at the expense of consistency. When a partition occurs, all nodes remain available but those at the wrong end of a partition might return an older version of data than others. (When the partition is resolved, the AP databases typically resync the nodes to repair all inconsistencies in the system.)
- CA database: A CA database delivers consistency and availability across all nodes. It can’t do this if there is a partition between any two nodes in the system, however, and therefore can’t deliver fault tolerance.
Understanding the CAP theorem can help you choose the best database when designing a microservices-based application running from multiple locations. For example, if the ability to quickly iterate the data model and scale horizontally is essential to your application, but you can tolerate eventual (as opposed to strict) consistency, an AP database like Cassandra or Apache CouchDB can meet your requirements and simplify your deployment. On the other hand, if your application depends heavily on data consistency — as in an eCommerce application or a payment service — you might opt for a relational database like PostgreSQL.
Thanks for reading!!