System Design, Chapter 5: Indexes in Databases
System Design, Chapter 5: Indexes in Databases
Clustered vs NonClustered, Clustered Indexes, NonClustered Indexes,Clustered and non-clustered indexes
In this blog, we are going to look how backend engineer deals with Fast retrieval of records from database.
Lets try to understand with the simple perspective, how things work and what is cluster and non cluster indexes.

Cluster indexes
We all have seen the landline time earlier, we used to have
telephone directory at our house, whenever we require any
number, we need to look up alphabetically and find out the
required number, that’s it you know what is cluster indexes.
Telephone
directory (single reference — Alphabetically ) — Organize the
data

One of the biggest advantages of Clustered Tables is that the data is physically sorted by the Clustered Key in your storage subsystem. You can compare a Clustered Table to a traditional phone book: the phone book is clustered/sorted by last name, which means that the last name Abhishek comes before Tarun, and Tarun comes before Umesh. Clustered Tables are therefore completely different from Heap Tables, where you have no physical sorting order.
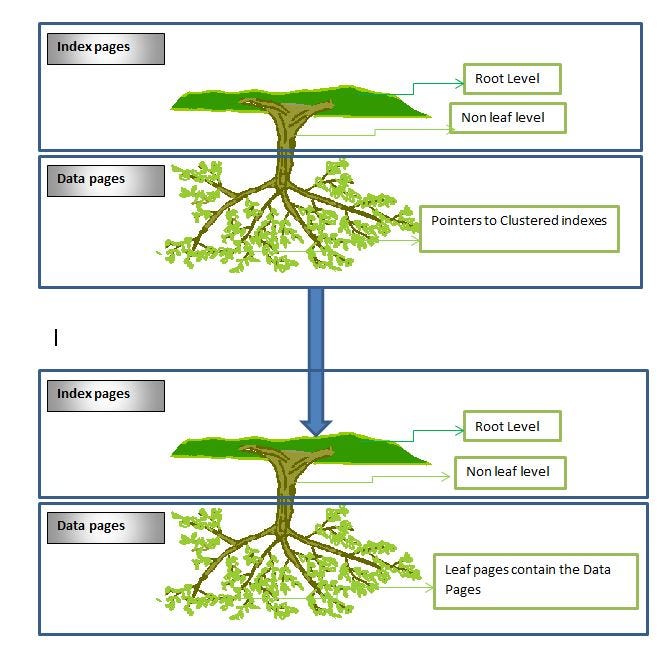
Lets try to understand with some of the diagrams how cluster will work at the backend.

Below is the diagrammatic representation of employee database using cluster indexes.

Non Cluster Indexes
We have known this from our school time when we used to look at the back of book indexes and able to find out which page need to look for which topic from the last subject index or book index at the back of book.
Book Last pages (indexes reference) — Based on content of page — Multiple topics can have same indexes.

Comparison
Clustered index saves an additional I/O that we have to do in non-clustered index to fetch the row data. This is because the complete row data resides in a clustered index leaf block whereas only the row locator is stored in a non-clustered index leaf block. So we save an additional I/O to get to the row.
This suggests that point lookups using clustered index will usually be faster than non-clustered index. This is true for both UNIQUE and NON-UNIQUE index type.
Similarly in case of range scan, clustered index will be faster. The performance gap between clustered and non-clustered index can be very significant if the scan happens to retrieve large amounts of data.
Disadvantages:
- Lookup on non-clustered index becomes costly. Let’s say there is a clustered index on column A and non-clustered index on column B. Once the non-clustered index is probed on key value of column B, we would have gotten the value of clustered index key (column A) from leaf block. This index key value of column A is then used to probe the clustered index (which is again a B-Tree traversal) and fetch the corresponding row from leaf block of clustered index.
- Every time the clustering key is updated, a corresponding update is required on non-clustered index as well because it stores the clustering key.
- Wide/Fat clustering key will increase the size of non-clustered index and also the size of each entry in index leaf block. Thus fewer entries will be packed per block and this will increase the disk I/O — more number of index pages/blocks will have to be read.
Advantages:
- Clustered Index requires the row data to be physically stored in sorted order (on the clustering key). An INSERT in a table (which is literally the clustered index here) has to maintain the invariant of “sorted order”. Therefore, it is very likely that rows will have to be moved around (row movement within a block or across blocks) to accommodate the new insert. If non-clustered index was storing the row locator, then every such INSERT will require an update to non-clustered index as well because the row locator would have changed due to row movement.
- But because non-clustered index stores the clustered index key instead of row locator, no such update is required due to row movement.
How Indexes are used by the Query Optimizer
Well-designed indexes can reduce disk I/O operations and consume fewer system resources therefore improving query performance. Indexes can be helpful for a variety of queries that contain SELECT, UPDATE, DELETE, or MERGE statements. Consider the query SELECT Title, HireDate FROM HumanResources.Employee WHERE EmployeeID = 250 in the EmpDataBase2018(Imaginary) database. When this query is executed, the query optimizer evaluates each available method for retrieving the data and selects the most efficient method. The method may be a table scan, or may be scanning one or more indexes if they exist.
When performing a table scan, the query optimizer reads all the rows in the table, and extracts the rows that meet the criteria of the query. A table scan generates many disk I/O operations and can be resource intensive. However, a table scan could be the most efficient method if, for example, the result set of the query is a high percentage of rows from the table.
When the query optimizer uses an index, it searches the index key columns, finds the storage location of the rows needed by the query and extracts the matching rows from that location. Generally, searching the index is much faster than searching the table because unlike a table, an index frequently contains very few columns per row and the rows are in sorted order.
The query optimizer typically selects the most efficient method when executing queries. However, if no indexes are available, the query optimizer must use a table scan. Your task is to design and create indexes that are best suited to your environment so that the query optimizer has a selection of efficient indexes from which to select.
With a clustered index the rows are stored physically on the disk in the same order as the index. Therefore, there can be only one clustered index.
With a non clustered index there is a second list that has pointers to the physical rows. You can have many non clustered indexes, although each new index will increase the time it takes to write new records.
It is generally faster to read from a clustered index if you want to get back all the columns. You do not have to go first to the index and then to the table.
Writing to a table with a clustered index can be slower, if there is a need to rearrange the data.
Summary
Clustered Indexes scale very well because internally they use a B-tree structure. SQL Server can make effective use of this structure when performing index seek operations on your table. But choosing the right and correct Clustered Key is an awful job.
Hope this article is useful for people looking to understand indexes in database at backend, Please ❤️ to recommend this post to others 😊. Let me know your feedback. :)