System Design, Chapter 4: Caching
System Design, Chapter 4: Caching
Cache, Memcached, Search engine caching, Global Caching and consistency
Its hard to remember everything but why can’t we make notes to recall it. This system design series in my publication contains all the basic and interesting facts about it.
In this blog, i will starting with some good terminology , remembering that will work for you during technical discussions. Let’s start with Why cache required?
The primary use of a cache memory is to speed up computation by exploiting patterns present in query streams. Since access to primary memory (RAM) is orders of magnitude faster than access to secondary memory (disk), the average latency drops significantly with the use of a cache. A secondary, yet important, goal is reducing the workload to back-end servers. If the hit rate is x, then the back-end servers receive 1 − x of the original query traffic.
Eviction Policy
A cache’s eviction policy tries to predict which entries are most likely to be used againin the near future, thereby maximizing the hit ratio. The Least Recently Used (LRU) policy is perhaps the most popular due to its simplicity, good runtime performance, and a decent hit rate in common workloads. Its ability to predict the future is limited to the history of the entries residing in the cache, preferring to give the last access the highest priority by guessing that it is the most likely to be reused again soon.
Modern caches extend the usage history to include the recent past and give preference to entries based on recency and frequency. One approach for retaining history is to use a popularity sketch (a compact, probabilistic data structure) to identify the “heavy hitters” in a large stream of events.
I’ll briefly mention several approaches here:
- Random Replacement (RR) — As the term suggests, we can just randomly delete an entry.
- Least frequently used (LFU) — We keep the count of how frequent each item is requested and delete the one least frequently used.
- W-TinyLFU — I’d also like to talk about this modern eviction policy. In a nutshell, the problem of LFU is that sometimes an item is only used frequently in the past, but LFU will still keep this item for a long while. W-TinyLFU solves this problem by calculating frequency within a time window. It also has various optimizations of storage.
Distributed cache
When the system gets to certain scale, we need to distribute the cache to multiple machines.
The general strategy is to keep a hash table that maps each resource to the corresponding machine. Therefore, when requesting resource A, from this hash table we know that machine M is responsible for cache A and direct the request to M. At machine M, it works similar to local cache discussed above. Machine M may need to fetch and update the cache for A if it doesn’t exist in memory. After that, it returns the cache back to the original server.
Memcached
is a simple in-memory key-value store, which primary use case is
shared cache for several processes within the server, or for
occasionally starting and dying processes (e. g. how PHP
processes behind Apache server used to do).
What it Does
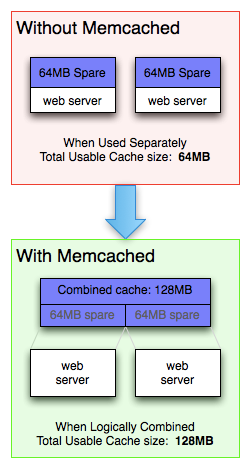
memcached allows you to take memory from parts of your system where you have more than you need and make it accessible to areas where you have less than you need.
memcached also allows you to make better use of your memory. If you consider the diagram to the right, you can see two deployment scenarios:
- Each node is completely independent (top).
- Each node can make use of memory from other nodes (bottom).
The first scenario illustrates the classic deployment strategy, however you’ll find that it’s both wasteful in the sense that the total cache size is a fraction of the actual capacity of your web farm, but also in the amount of effort required to keep the cache consistent across all of those nodes.
With memcached, you can see that all of the servers are looking into the same virtual pool of memory. This means that a given item is always stored and always retrieved from the same location in your entire web cluster.
Also, as the demand for your application grows to the point where you need to have more servers, it generally also grows in terms of the data that must be regularly accessed. A deployment strategy where these two aspects of your system scale together just makes sense.
The illustration to the right only shows two web servers for simplicity, but the property remains the same as the number increases. If you had fifty web servers, you’d still have a usable cache size of 64MB in the first example, but in the second, you’d have 3.2GB of usable cache.
Of course, you aren’t required to use your web server’s memory for cache. Many memcached users have dedicated machines that are built to only be memcached servers.
Concurrency
Concurrent access to a cache is viewed as a difficult problem because in most policies every access is a write to some shared state. The traditional solution is to guard the cache with a single lock. This might then be improved through lock striping by splitting the cache into many smaller independent regions. Unfortunately that tends to have a limited benefit due to hot entries causing some locks to be more contented than others. When contention becomes a bottleneck the next classic step has been to update only per entry metadata and use either a random sampling or a FIFO-based eviction policy. Those techniques can have great read performance, poor write performance, and difficulty in choosing a good victim.
An alternative is to borrow an idea from database theory where writes are scaled by using a commit log. Instead of mutating the data structures immediately, the updates are written to a log and replayed in asynchronous batches. This same idea can be applied to a cache by performing the hash table operation, recording the operation to a buffer, and scheduling the replay activity against the policy when deemed necessary. The policy is still guarded by a lock, or a try lock to be more precise, but shifts contention onto appending to the log buffers instead.
Search Engine Caching
Search engines are essential services to find the content on the Web. Commercial search engines like Yahoo! have over a hundred billion documents indexed, which map to petabytes of data. Searching through such an enormous amount of data is not trivial, especially when serving a large num- ber of queries concurrently. Thus, search engines rely upon systems comprising large numbers of machines grouped in clusters by functionality, such as index servers, document servers, and caches.
In a typical search engine, there are five types of data items that are accessed or generated during the search process: query results, precomputed scores, posting lists, precomputed intersections of posting lists, and documents.
Query processing overview
Web search engines are composed of multiple replicas of large search clusters. Each query is assigned to an individual search cluster, based on the current workload of clusters or based on a hash of the query string. A search cluster is composed of many nodes over which the documents are partitioned. Each node builds and maintains an index over its local document collection. All nodes in the cluster contribute to processing of a query.
Query processing involves a number of steps: issuing the query to search nodes, computing a partial result ranking in all nodes, merging partial rankings to obtain a global top-k result set, computing snippets for the top-k documents, and generating the final result page.

Five-level static caching
Herein, we describe a five-level cache architecture for static caching in search engines. Steps mentioned in value column refers to figure 1 for your reference.
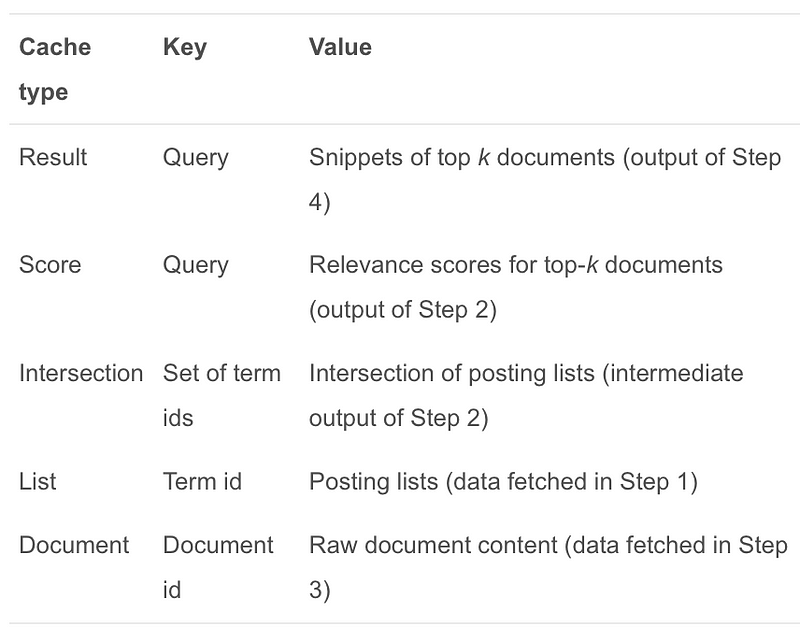
Below figure illustrates the interaction between different cache components.
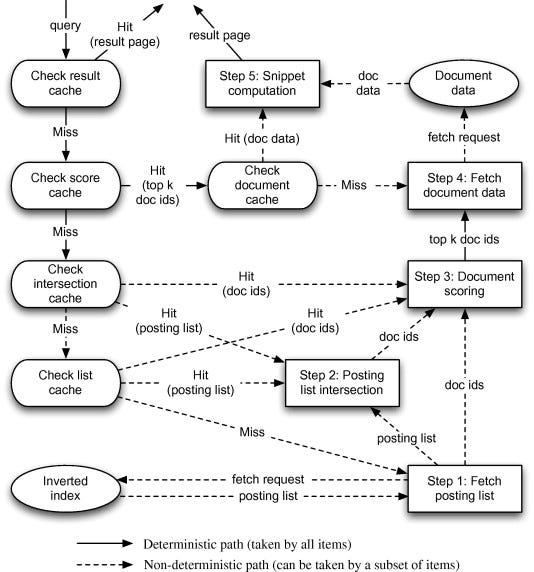
Bonus time:
System Design: Global Caching and consistency
Scenario: Lets take an example of Twitter. There is a huge cache which gets updated frequently. For example: if person Foo tweets and it has followers all across the globe. Ideally all the caches across all PoP needs to get updated. i.e. they should remain in sync.
How does replication across datacenter (PoP) work for realtime caches ? What tools/technologies are preferred ? What are potential issues here in this system design ?
Solution: I would tackle the problem from a slightly different angle: when a user posts something, that something goes in a distributed storage (not necessarily a cache) that is already redundant across multiple geographies.I would also presume that, in the interest of performance, these nodes are eventually consistent.
Now the caching. I would not design a system that takes care of synchronising all the caches each time someone does something. I would rather implement caching at the service level. Imagine a small service residing in a geographically distributed cluster. Each time a user tries to fetch data, the service checks its local cache — if it is a miss, it reads the tweets from the storage and puts a portion of them in a cache (subject to eviction policies). All subsequent accesses, if any, would be cached at a local level.
In terms of design precautions:
- Carefully consider the AZ(Availability Zone) topology in order to ensure sufficient bandwidth and low latency
- Cache at the local level in order to avoid useless network trips
- Cache updates don’t happen from the centre to the periphery; cache is created when a cache miss happens
- I am stating the obvious here, implement the right eviction policies in order to keep only the right objects in cache
- The only message that should go from the centre to the periphery is a cache flush broadcast (tell all the nodes to get rid of their cache)
Hopefully this is good food for thought considering time during technical discussion.
Hope this article is useful for people looking to understand caching at backend, Please ❤️ to recommend this post to others 😊. Let me know your feedback. :)