Approach a System Design Interview
Approach a System Design Interview
This blogs teaches you how to handle the system design interview with a systematic approach in a short time. As we all know,this topic is very vast and continuous reading of topics, book and hands on required to become expert on it.
I am going to create few blogs which will be focused on clearing system design interviews.
Remember: Don’t be scared by system design interview questions Unless you claim to know how to design large systems, your interviewer probably won’t expect you to know this stuff automatically They just want to see how you tackle these problems.
Lets starts as a beginner, what a interviewer is expecting from us?. There are so many concepts, directions, components, pros and cons that one cannot describe all of them in 4 hours, let alone in 45 minutes.
When companies ask design questions, they want to evaluate your design skills and experience in designing large scale distributed systems. How well you do in such interviews often dictates your hiring level (and in some cases even salary). Hence, it’s in your best interest to have a plan and prepare for these interviews. So Lets start preparing…
Question: What should be our approach towards system design interview?
Answer: Decide some steps which you are going to follow and wrap a discussion with in 30~45 minutes. As we all know, all developer don't work on system side…Right!
We are going to create few steps to solve the design problem and we will try to stick it during our interviews so that we know what are we talking…right!
Remember:
Step 1: Requirement Gathering (Discuss with interviewer for 2 minutes)
Step 2: System interface definition (Take a pause for 1 or 2 minute , note down your thoughts and explain what do you have on it in 5 minutes)
Step 3: Capacity estimation (Write down your big guns, its show time for 10~15 minutes)
Step 4: Defining the data model(Fire everything for 10~15 minute, Points to cover: Entities, Interaction with each other, Data management like storage, transfer, encryption, etc)
Step 5: High-level design (Show case your drawing skills in 3~5 minutes and try to wrap it)
If you will remember these steps and have some basic knowledge of terminologies used in system design , you will clear out 1–2 round of interviews easily but some of the companies are only taking system design round , You need more time and knowledge to work on it. We will be focusing on both the aspects (part interviews and complete interviews).
We will be covering at least these topic in blog series but there will be bonus time.
- Scalability
- Sharding or Data Partitioning
- Load Balancing
- Caching
- Indexes
- Proxies
- Queues
- Redundancy and Replication
- SQL vs. NoSQL
- CAP Theorem
- Consistent Hashing
- Security
- Analytics
Chapter 1: Overview of Scalability, Horizontal Scaling, and Vertical Scaling
Scaling a database can become necessary for a variety of reasons:
- Support a higher volume of users
- Provide better performance for existing users
- Store a larger volume of data
- Improve system availability
- Geographic dispersion (generally related to performance and availability)
Options for scaling a database can be grouped into two major categories: Vertical and Horizontal. Scaling vertically generally describes adding capacity to the existing database instance(s) without increasing the number of servers or database instances. Horizontal Scaling, on the other hand, refers the alternative approach of adding servers and database instances.

Scaling Vertically
The easiest way to increase the capacity of a MySQL database is to upgrade the server hardware. Most often, this means adding CPU and/or RAM, but can also include disk I/O capacity. Scaling vertically can be done by upgrading existing server hardware or by moving to a new server.
- Easiest, simplest option for scaling your MySQL database
- Doesn’t improve availability (db is still running on a single box)
- Good for boosting CPU and RAM, but limited potential for improving network I/O or disk I/O
- Beefy hardware is expensive
- There is a finite limit to the capacity achievable with vertical scaling
Scaling Horizontally
For projects with requirements for high availability or failover, adding additional servers can be the right solution. Horizontal scaling can be done with a variety of configurations: Active-Passive, Master-Slave, Cluster, or Sharding.
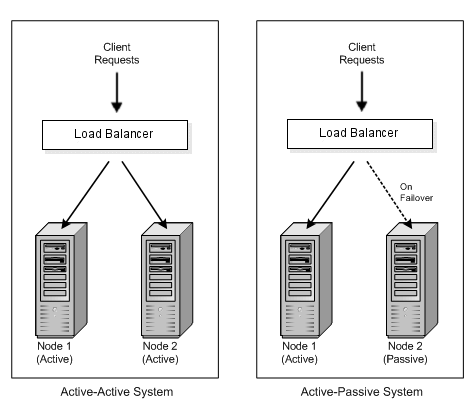
Active-Passive
With two database instances, one is the active instance and the other is the passive. All queries (reads and writes) are directed to the active instance. Write operations are replicated to the passive instance to keep it in sync. In the event of failure of the active instance, query and update traffic is redirected to the passive instance. For more information on MySQL replication, look here: http://dev.mysql.com/doc/refman/5.1/en/replication.html.
- Improves availability and failover
- Doesn’t improve capacity or performance (over a single instance of the same size)
- Redirecting traffic from the active instance to the passive can be done automatically (recommended) with a load-balancer or switch, or can be done manually using a VIP or internal DNS configuration change
Master-Slave
Using two or more database instances, one instance is the master and the others are slaves. All writes are routed to the master instance, then replicated to the slaves. Read operations are routed to the slave instances. In the event of failure of the master, one of the slave instances must be designated as the new master and update operations rerouted.
- An unlimited number of slave instances can be added, but only one instance can be the master
- Great for applications with mostly READ operations
- Good for addressing I/O (network or disk) bottlenecks
- Good for geographic dispersion
- Requires application logic to separate read and write operations
- Replication is asynchronous, so instances are not guaranteed to be in sync
- Master instance can be scaled vertically

Bonus Time:
Question: Design the data structures for a very large social network. Describe how you would design an algorithm to show the connection, or path, between two people (e g , Me -> Kumar-> Verma-> Atul-> You)?
Approach: Forget that we’re dealing with millions of users at first Design this for the simple case.
We can construct a graph by assuming every person is a node and if there is an edge between two nodes, then the two people are friends with each other class Person { Person[] friends; // Other info }
If I want to find the connection between two people, I would start with one person and do a simple breadth first search But… oh no! Millions of users! When we deal with large social network, means that our simple Person data structure from above doesn’t quite work — our friends may not live on the same machine as us.
Instead, we can replace our list of friends with a list of their IDs, and traverse as follows:
1 For each friend ID: int machineID = lookupMachineForUserID(id);
2. Person friend = lookupFriend(machineID, ID);
There are more optimizations and follow up questions here than we could possibly discuss, but here are just a few thoughts:
Optimization: Reduce Machine Jumps, Jumping from one machine to another is expensive Instead of randomly jumping from machine to machine with each friend, try to batch these jumps — e g , if 5 of my friends live on one machine, I should look them up all at once Optimization: Smart Division of People and Machines People are much more likely to be friends with people who live in the same country as them Rather than randomly dividing people up across machines, try to divvy them up by country, city, state, etc This will reduce the number of jumps
Question: Breadth First Search usually requires “marking” a node as visited. How do you do that in this case?
Approach: Usually, in BFS, we mark a node as visited by setting a flag visited in its node class. Here, we don’t want to do that (there could be multiple searches going on at the same time, so it’s bad to just edit our data) In this case, we could mimic the marking of nodes with a hash table to lookup a node id and whether or not it’s been visited.
Other Follow-Up Questions: In the real world, servers fail, How does this affect you? How could you take advantage of caching? Do you search until the end of the graph (infinite)? How do you decide when to give up?
In real life, some people have more friends of friends than others, and are therefore more likely to make a path between you and someone else How could you use this data to pick where you start traversing?
As we can see, there is lot to learn so lets learn!!
Like, Subscribe for more blogs.